


新智元报道
编辑:Aeneas KingHZ
【新智元导读】超越DeepSeek-R1的英伟达开源新王Llama-Nemotron,是怎么训练出来的?刚刚放出的论文,把一切细节毫无保留地全部揭秘了!
现在,英伟达Llama-Nemotron系列模型,正式超越DeepSeek-R1!
而且,这些模型已经全部开源了。
换句话说,在推理吞吐量和内存效率上显著超越DeepSeek-R1的一系列推理模型,已经开源可用了。
超越DeepSeek-R1的模型,究竟是怎么炼出的?
就在刚刚,英伟达发布了技术报告中,揭秘了模型训练的关键——
· 利用合成数据监督微调+强化学习,全面提升模型的推理能力
· 从头构建完善的后训练流程

论文链接:https://arxiv.org/abs/2505.00949
发布之后,英伟达的这一系列模型在业界引起不小的轰动。
根据人工分析智能指数,截至2025年4月,Llama-Nemotron-Ultra被认为是目前「最智能」的开源模型。
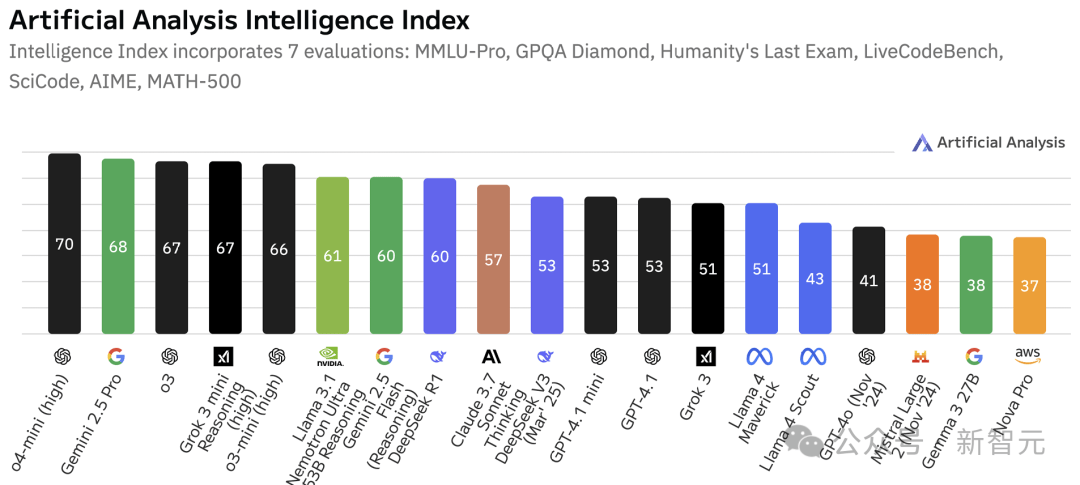
这次,英伟达一口气推出了Llama-Nemotron系列三个模型——LN-Nano 8B,LN-Super 49B和LN-Ultra 253B。
值得一提的是,LN-Ultra不仅在性能上超越了DeepSeek-R1,还能在单个8xH100节点上运行,推理吞吐量更高。
这些模型针对高吞吐量推理进行了优化,同时保持强大的推理能力和最多128K的上下文长度。
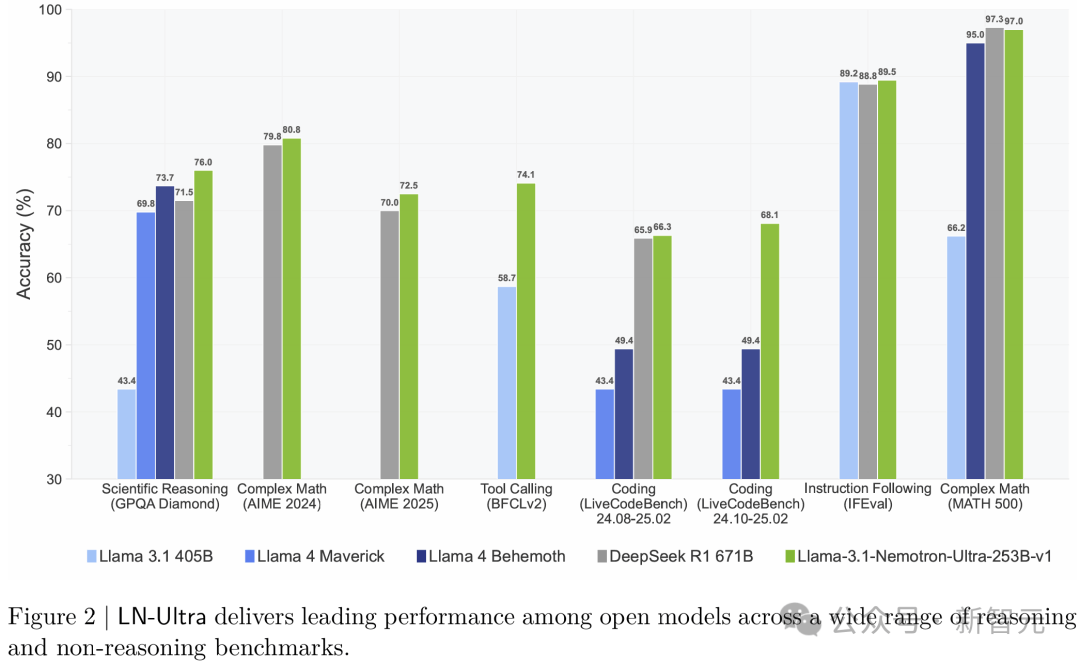
LN-Ultra在各类推理任务中展现出领先的开源模型性能
并且,在全球AI开源届,英伟达首次推出了推理开关功能,用户只需通过系统提示词「detailed thinking on/off」就可以动态切换标准聊天模式和推理模式。
这种设计让模型既能满足日常通用需求,也能胜任复杂的多步骤推理,无需使用不同的模型或架构。
揭秘构建过程
Llama-Nemotron模型的构建,分为五个阶段。
第一阶段:利用神经架构搜索(NAS)在Llama 3系列模型基础上优化推理效率,并引入前馈网络融合(FFN Fusion)。
第二阶段:通过知识蒸馏和继续预训练来恢复模型性能。
第三阶段:进行有监督微调(SFT),结合标准指令数据和来自DeepSeek-R1等强大教师模型的推理过程,从而让模型具备多步骤推理能力。
第四阶段:在复杂的数学和STEM数据集上进行大规模强化学习,这是学生模型能够超越教师模型能力的关键一步。对于LN-Ultra,这一阶段在GPQA-D基准测试上带来了显著性能提升,确立其作为当前开源领域科学推理最强模型的地位。
为了支持如此大规模的强化学习训练,团队专门开发了新的训练框架,包含多项优化措施,其中最重要的是支持 FP8精度的生成能力。
最后一个阶段:简短的对齐训练,重点在于指令跟随和符合人类偏好。
全新架构设计:优化推理效率
借助神经架构搜索Puzzle框架,LN-Super和LN-Ultra优化了模型推理效率。
Puzzle能够在实际部署限制下,将大语言模型转化为更适配硬件运行的高效版本,如图3所示。
通过「逐块局部蒸馏」的方式,开发者利用Llama 3 Instruct构建了替代Transformer模块的库。
在这个过程中,每个模块都会被独立且并行地训练,逼近原始模块的功能,同时优化计算性能。
这样,每个替代模块都具有特定的「精度-效率」权衡特性:有些模块虽然更高效,但可能会带来一定的质量下降,从而形成一种在计算成本与模型准确性之间的明确取舍。
这些模块的变体包括:
-
注意力机制移除:某些模块完全省略了注意力机制,从而降低了计算量和KV缓存的内存消耗。
-
可变的FFN维度:前馈网络的中间维度被调整,能以不同粒度对模型进行压缩。
注意力机制移除:某些模块完全省略了注意力机制,从而降低了计算量和KV缓存的内存消耗。
可变的FFN维度:前馈网络的中间维度被调整,能以不同粒度对模型进行压缩。
在构建好模块库后,Puzzle会从每一层中选择一个模块,组装出一个完整的模型。
这个选择过程由混合整数规划(MIP)求解器控制,它会根据一系列约束条件(如硬件兼容性、最大允许延迟、内存预算或期望的推理吞吐量)来找出最优配置。
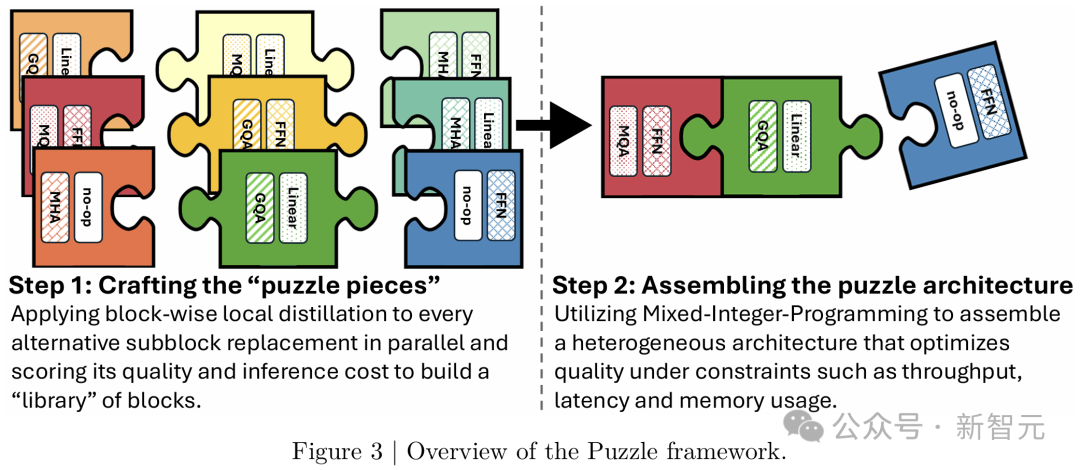
Puzzle框架概览
垂直压缩与FFN融合
在LN-Ultra模型中,研究者引入了一项额外的压缩技术,称为FFN Fusion(前馈网络融合),用于减少模型的序列深度并提升推理延迟效率。
Puzzle在移除部分注意力层后,模型结构中出现的一种特性:模型中常会出现多个连续的FFN块。
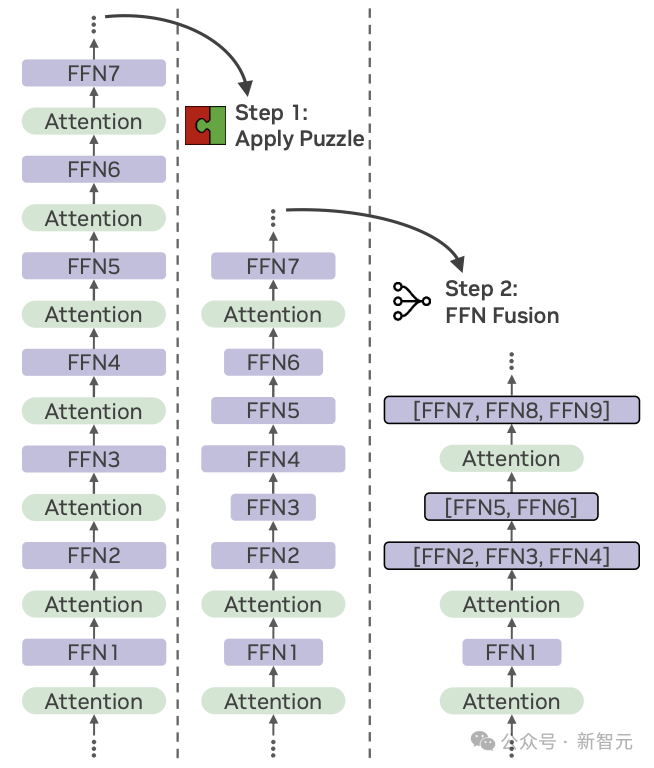
这种替换方式在不牺牲模型表达能力的前提下,减少了顺序计算的步骤,显著提升了计算资源的利用率——特别是在多GPU环境中,跨层通信开销不可忽视的情况下,效果尤为明显。
图4展示了在GPQA-Diamond准确率(%)与处理吞吐量(token/秒)之间的权衡。
值得注意的是,LN-Ultra始终在准确性和效率上优于DeepSeek-R1和Llama-3.1-405B,取得了准确性和效率的最佳平衡。
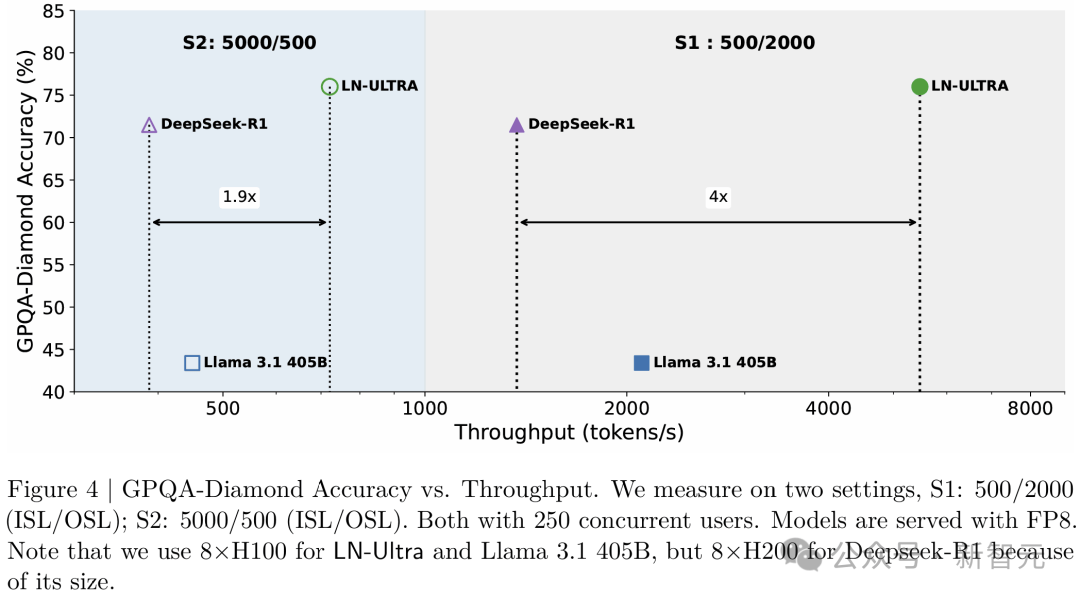
GPQA-Diamond模型的精确度与吞吐量对比
NAS后训练:知识蒸馏与持续预训练
在神经架构搜索(NAS)阶段之后,LN-Super和LN-Ultra都进行了额外的训练,以提升模块之间的兼容性,并恢复在模块替换过程中可能出现的质量损失。
-
LN-Super使用Distillation Mix数据集,在知识蒸馏目标下训练了400亿个token。
-
LN-Ultra首先使用相同的蒸馏数据集进行知识蒸馏训练,训练了650亿个token;随后又在Nemotron-H第四阶段预训练数据集上继续训练了880亿个token。
LN-Super使用Distillation Mix数据集,在知识蒸馏目标下训练了400亿个token。
LN-Ultra首先使用相同的蒸馏数据集进行知识蒸馏训练,训练了650亿个token;随后又在Nemotron-H第四阶段预训练数据集上继续训练了880亿个token。
这一最终的预训练步骤,使LN-Ultra不仅追平了参考模型Llama 3.1-405B-Instruct的表现,还在关键基准测试中实现了超越。
这就,表明通过简短的蒸馏与预训练,可以在激进的架构优化和高模型性能之间实现兼容。
监督微调
想让Llama-Nemotron模型拥有超厉害的推理能力?
监督微调(Supervised Fine-Tuning,SFT)这一步简直就是「神助攻」。
前面的开发阶段,团队主要在研究怎么让模型架构更高效,怎么把海量知识塞进去。
而SFT就像给模型请了一位「私人教练」,专门针对特定任务的推理步骤,带着它从DeepSeek-R1这些「学霸」模型身上,偷师推理技巧。
不过要想让模型真正拥有扎实的推理功底,大规模、高质量的推理训练数据必不可少。
合成数据
研究者为监督微调精心整理了包含推理和非推理的数据样本。
对于推理样本,他们在系统指令中加入「detailed thinking on」(开启详细思考),而对于非推理样本,则使用「detailed thinking off」(关闭详细思考)。
这种设置,使模型能够在推理阶段根据提示内容切换推理行为。
为推理,精心准备了数学、代码等相关领域的合成数据。
为了训练模型遵循「推理开关」指令,研究者构建了成对的数据集,其中每个提示都对应一个带推理的回复和一个不带推理的回复。
这种配对方式,使模型能够根据系统指令学习调节其推理行为。
随后会依据标准答案或奖励模型对这些回复进行筛选。
微调流程
在指令微调数据上,所有模型的训练,均采用token级交叉熵损失。
在大多数训练设置中,推理数据和非推理数据会被混合在一起,形成训练批次,其中每个提示都会根据系统指令「detailed thinking on/off」的条件,与相应的响应配对。
延长训练至多轮周期能提升性能,对小模型尤为明显。
这次主要使用NeMo-Aligner来进行强化学习训练,支持GRPO以及异构模型的训练。

论文链接:https://arxiv.org/abs/2405.01481
生成阶段使用vLLM实现,训练阶段则使用Megatron-LM。
训练和推理阶段共用同一批GPU,在同一设备上完成。

整个训练过程中,他们共使用了72个节点,每个节点配备8张H100 GPU。
生成阶段采用FP8精度,训练阶段采用BF16精度,优化器状态使用FP32。
每个阶段维护一份独立的模型权重,并在每一步开始时进行同步。
强化学习:超越R1推理能力的关键
监督微调(SFT)可以让模型从强大的教师模型中提炼知识,从而获得出色的能力。
然而,知识蒸馏本质上为学生模型的性能设定了上限,特别是当学生模型的基础模型能力不超过教师模型时。
通过监督微调,LN-Ultra的性能可以接近DeepSeek-R1,但无法超越它。
为了使学生模型超越教师模型,大规模强化学习(RL)是一种可行的方法,因为它允许模型持续探索新的可能性并进行自我学习。
由于资源限制,研究者仅对LN-Ultra应用推理RL,结果得到超越教师模型的学生模型。
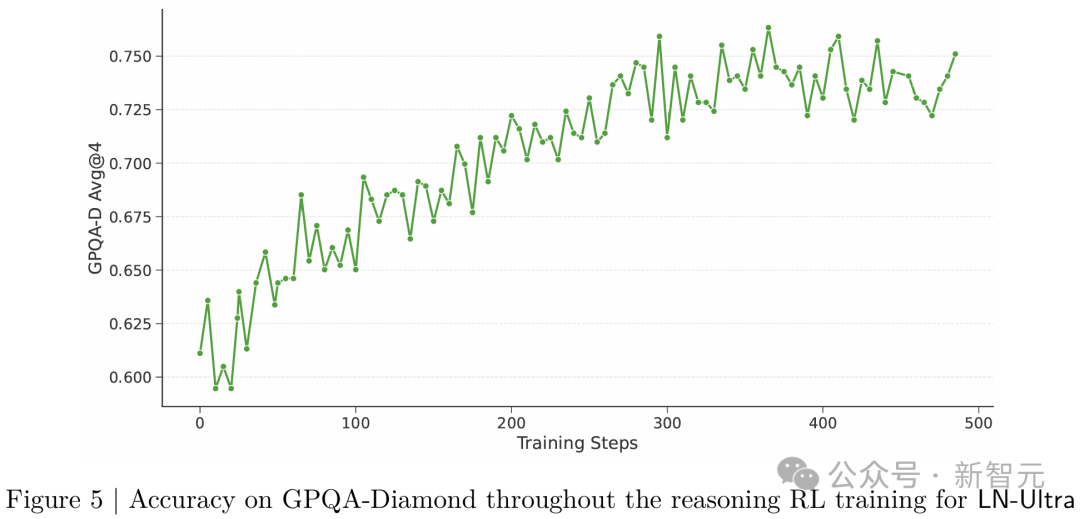
在整个推理强化学习训练过程中,在GPQA-Diamond数据集上,LN-Ultra的准确性
训练流程
对于LN-Ultra,研究者通过大规模强化学习(RL)增强它的科学推理能力,采用DeepSeek-R1同款的分组相对策略优化(GRPO)算法。
整个训练过程大约需要14万H100小时,持续训练模型直至其在推理任务上实现收敛。
图5显示了训练过程中GPQA-Diamond的准确率得分。
奖励机制设计包含两类:
-
准确性奖励:基于标准答案(数值/句子/段落),调用Llama-3.3-70B-Instruct模型判断预测结果匹配度
-
格式奖励:遵循DeepSeek-AI的方案,强制模型在「详细思考」模式下用<think>标签包裹推理过程,非该模式时禁止出现此类标签
准确性奖励:基于标准答案(数值/句子/段落),调用Llama-3.3-70B-Instruct模型判断预测结果匹配度
格式奖励:遵循DeepSeek-AI的方案,强制模型在「详细思考」模式下用<think>标签包裹推理过程,非该模式时禁止出现此类标签
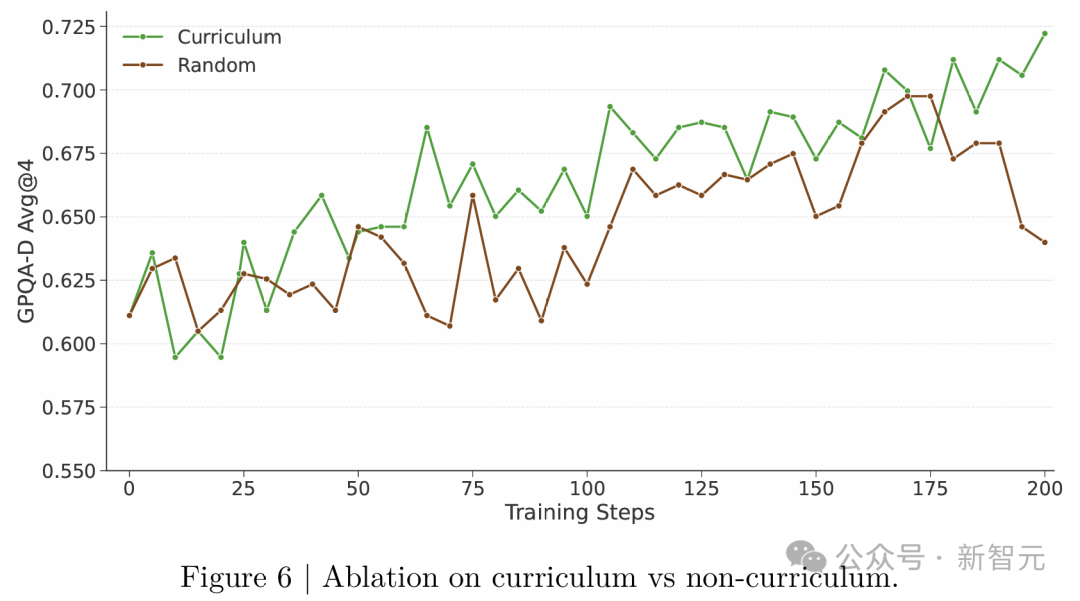
研究团队还对数据进行预处理,包括数据过滤和课程训练(curriculum training)。
-
数据筛选:预先使用LN-Super对每个问题生成8条响应,剔除通过率≥75%的简单样本
-
课程训练:采用基于通过率的渐进式批次分配(图6验证其有效性)
-
动态分布:以高斯函数建模批次难度,初期侧重高通过率(简单)样本,后期转向低通过率(困难)样本
-
填充逻辑:优先按目标分布分配样本,剩余容量从最大剩余样本池补充
-
批内处理:同批次样本随机打乱以保持多样性
数据筛选:预先使用LN-Super对每个问题生成8条响应,剔除通过率≥75%的简单样本
课程训练:采用基于通过率的渐进式批次分配(图6验证其有效性)
-
动态分布:以高斯函数建模批次难度,初期侧重高通过率(简单)样本,后期转向低通过率(困难)样本
-
填充逻辑:优先按目标分布分配样本,剩余容量从最大剩余样本池补充
-
批内处理:同批次样本随机打乱以保持多样性
动态分布:以高斯函数建模批次难度,初期侧重高通过率(简单)样本,后期转向低通过率(困难)样本
填充逻辑:优先按目标分布分配样本,剩余容量从最大剩余样本池补充
批内处理:同批次样本随机打乱以保持多样性
用于偏好优化的强化学习
在完成科学推理训练之后,研究者对LN-Super和LN-Ultra模型进行了一个简短的强化学习阶段,重点提升其指令跟随能力。
研究者还使用RLHF对模型的通用帮助能力和聊天表现进行优化,同时保留了模型在数学、科学等其他领域的能力。
如表4所示,LN-Super在Arena Hard测试中取得了88.3的高分,超越了专有模型如Claude 3.5 Sonnet和GPT-4o-2024-05-13,也优于体量更大的开源模型。
为了实现这一结果,他们采用了「在线RPO」(OnLine Reward-Policy Optimization)方法,最大化模型在HelpSteer2数据集上的预测奖励,奖励模型使用的是Llama-3.1-Nemotron-70B-Reward。
两轮在线RPO训练将Arena Hard得分从69.1提升到88.1。
对于LN-Ultra,他们使用类似流程,但采用了GRPO。
对于LN-Nano,他们进行了两轮离线RPO训练,使用基于策略生成的训练数据。
在第一轮中,结合推理类和非推理类数据,并配合适当的系统提示词,以优化模型的推理控制能力。第二轮则专注于提升指令跟随能力。
评估结果
研究者在两个基准类别上评估所有Llama-Nemotron模型的性能:推理任务和非推理任务。
推理类基准包括:AIME24和AIME25、GPQA-Diamond、LiveCodeBench以及MATH500。
非推理类基准包括:用于指令遵循评估的IFEval、用于函数调用工具使用评估的BFCL V2 Live以及用于评估对人类对话偏好对齐度的Arena-Hard。
表3显示,尽管模型体积较小,LN-Nano在所有推理类基准测试中都取得了出色的表现。
这表明,监督微调流程和精心策划的推理数据集,在将结构化推理能力迁移至小型模型方面是有效的。
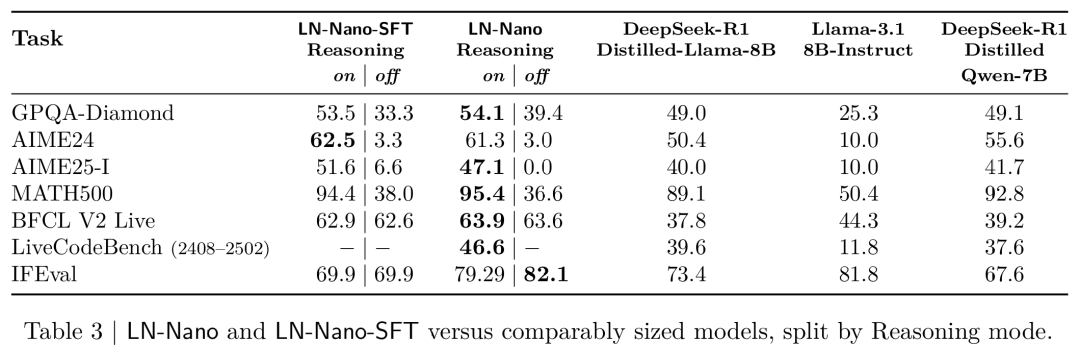
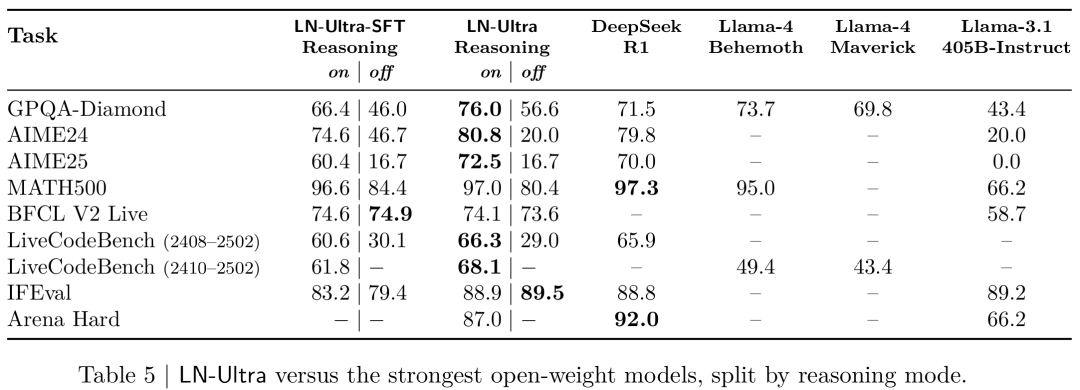
表4将LN-Super与其参数规模相近的其他模型进行了对比,可见这个模型在推理任务和非推理任务中都表现出强劲的竞争力。
在「推理关闭」模式下,LN-Super的表现与其蒸馏来源模型Llama-3.3-70B相当;在「推理开启」模式下,则超越了其他竞品模型,例如DeepSeek-R1-Distilled-Llama-70B,在保持良好指令遵循能力的同时展现出强大的推理能力。
这些结果表明,LN-Super是一个兼具推理优化模型和非推理模型优点的通用模型,适用于日常助手型任务和结构化推理任务。
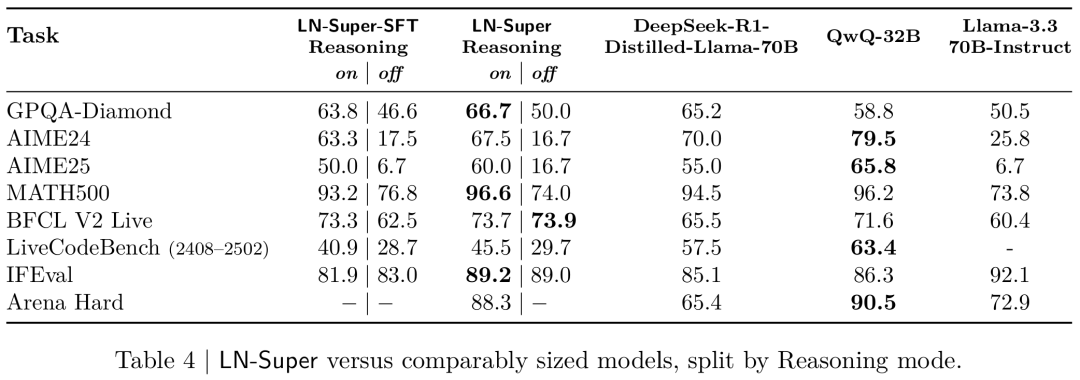
表5显示,LN-Ultra 在推理和非推理基准测试中,与所有现有的开源权重模型相比表现持平或更优。它在GPQA上达到了开源模型中的最先进水平,充分证明了英伟达研究者大规模强化学习训练方法的有效性。
与DeepSeek-R1需要使用8×H200的硬件配置不同,LN-Ultra专门优化为可在单个8×H100节点上高效运行,从而提供更高的推理吞吐量和部署效率。
从表5可见,LN-Ultra的SFT阶段已经在多个推理基准测试(包括GPQA和AIME)上接近或达到DeepSeek-R1的性能。
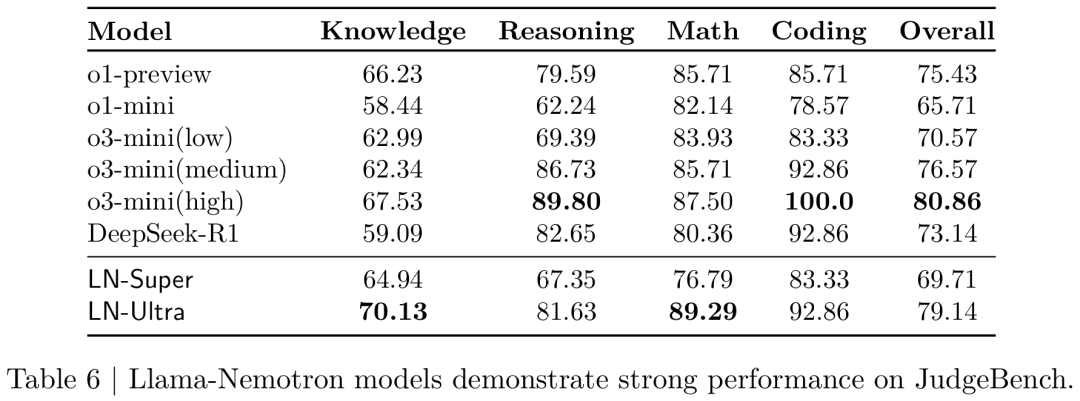
除了模型原本接受训练的推理和对话能力之外,他们还对模型在一个分布外任务。
具体来说,模型在JudgeBench数据集上进行了测试,要求区分高质量与低质量的回答。
如表6所示,新模型在该任务上表现优于当前顶尖的专有模型和开源模型。
其中,LN-Ultra成为表现最好的开源模型,明显超过了 DeepSeek-R1,仅次于专有模型 o3-mini(high)。
此外,LN-Super 的表现也超过了o1-mini,这说明新模型在各类任务中具备很强的泛化能力。
参考资料:
https://arxiv.org/abs/2505.00949
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏





